

平均修復時間通常縮寫為 MTTR,是維護與可靠性管理中的一項指標,用來衡量將發生故障的資產、設備、機器、軟體服務、網絡組件或生產系統恢復到正常運作狀態所需的平均時間。它關注故障發生之後的修復過程,因此是控制停機時間、提升服務效率、增強運營韌性和制定維護計劃的重要參考。
在工廠、數據中心、通信網絡、交通系統、電力設施、醫院、樓宇和 IT 環境中,故障並不總是能夠完全避免。真正關鍵的是組織能以多快的速度發現問題、診斷原因、完成修復、測試結果,並讓系統重新投入服務。MTTR 可以幫助團隊以可衡量的方式理解自身的恢復能力。
可靠性管理中的基本含義
Mean Time to Repair 表示多個故障事件中的平均修復時長。它不是兩次故障之間的間隔時間,也不是某個系統在較長週期內的總停機時間。它回答的是一個非常實際的問題:當某個對象發生故障時,通常需要多長時間才能修好?
這一指標廣泛用於維護工程師、設施管理人員、IT 服務團隊、可靠性工程師、設備製造商和運營管理人員。較低的 MTTR 通常意味著恢復更快、維護響應更好、備件準備更充分、流程更清晰,故障排查也更有效。
MTTR 實際衡量的內容
MTTR 通常包含使資產重新恢復工作狀態所需的主動修復時間。根據不同組織對指標的定義,它可能包括故障確認、診斷、備件更換、配置恢復、功能測試以及最終的服務恢復。
例如,如果一臺生產設備因為傳感器故障而停機,修復時間可能包括技術人員派遣、傳感器檢查、更換、校準和重啟驗證。如果一臺伺服器發生故障,修復時間可能包括事件分析、部件更換、數據恢復、重新啟動和服務驗證。
為什麼必須明確指標定義
不同組織可能會以略有差異的方式計算 MTTR。有些團隊從故障被報告的時間開始計算,有些團隊從維修工作真正開始時計算。有些會把等待備件的時間計入其中,而有些只統計實際動手維修的技術時間。
因此,在用 MTTR 做績效對比之前,必須先把定義說明清楚。如果沒有一致的統計口徑,這個指標就可能產生誤導。某個維護團隊看起來較慢,可能只是因為它把等待、審批或路途時間都計入了計算,而另一個團隊只統計實際維修活動。
計算方式如何運作
標準的 MTTR 公式非常簡單。把特定週期內所有修復事件的修復時間相加,然後除以修復事件總數,結果就表示恢復故障資產或系統所需的平均時間。
例如,五次維修分別耗時 2 小時、3 小時、1 小時、4 小時和 5 小時,總修復時間就是 15 小時。15 小時除以 5 次修復事件,MTTR 等於 3 小時。這表示每次維修平均需要 3 小時。
修復時間數據採集
準確的 MTTR 依賴準確的維修記錄。團隊需要記錄故障何時被發現、何時開始修復、採取了哪些操作、服務何時恢復以及修復是否已經驗證。維護管理系統、工單平台、SCADA 日誌、服務台和計算機化維護管理系統都可以幫助採集這些資訊。
手工記錄也可以使用,但必須保持一致。如果技術人員忘記關閉工單、記錄的維修時間不完整,或以不同方式分類事件,最終得到的 MTTR 數值可能無法反映真實的運營表現。
設備維修的簡單示例
假設某個設施中的通風機組在一個月內發生三次故障。第一次維修用時 90 分鐘,第二次用時 120 分鐘,第三次用時 60 分鐘,總修復時間為 270 分鐘。
按照 MTTR 公式,270 分鐘除以 3 次修復事件,結果為 90 分鐘。因此该通風機組的 MTTR 為 90 分鐘。設施管理人員可以用這個數字評估響應效率、技術人員工作負荷、備件可用性以及是否需要加強預防性維護。
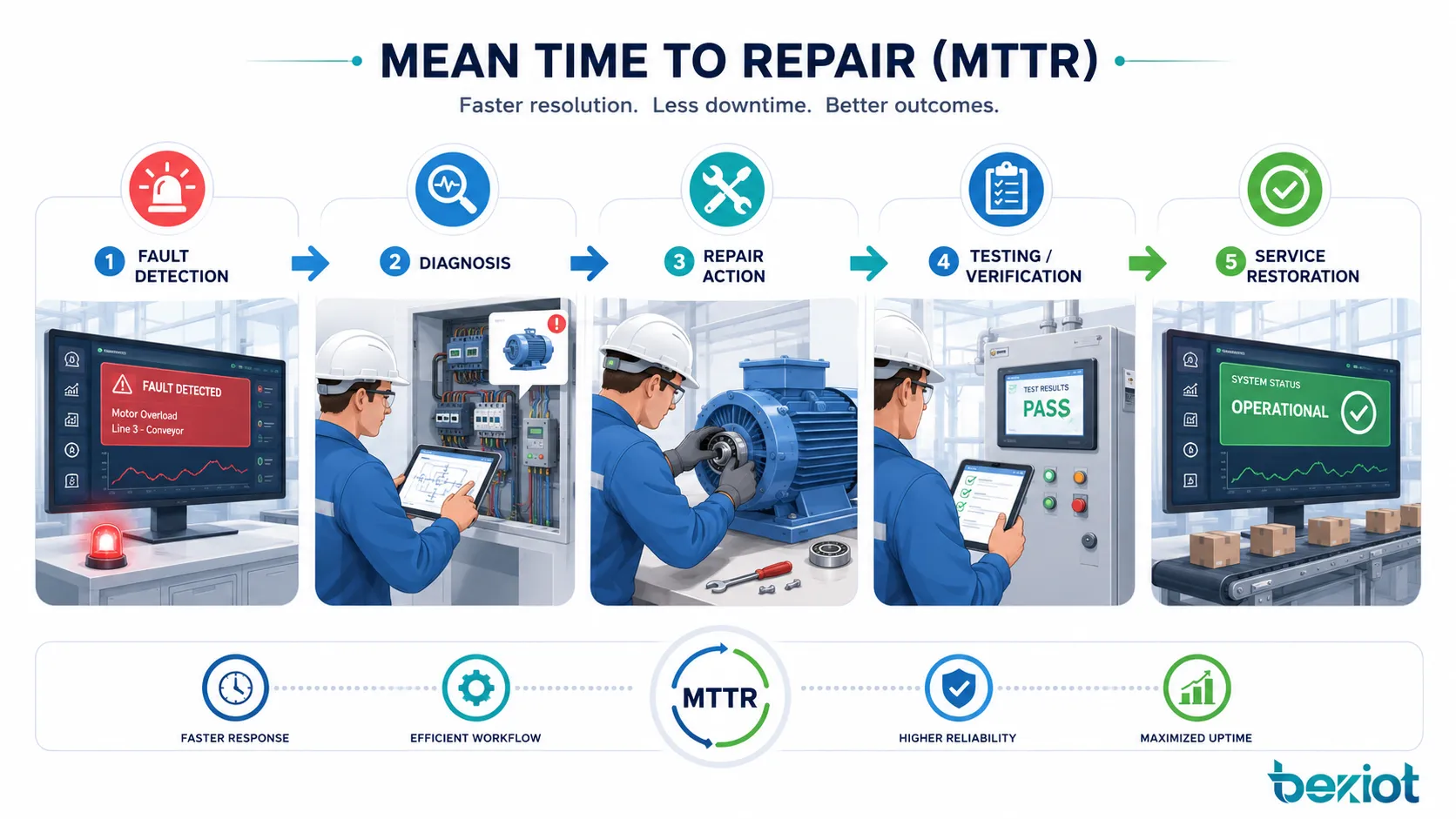
一個修復週期中會發生什麼
MTTR 不只是一個數學平均值。它反映了每次故障背後的完整修復流程。較長的修復時間可能來自故障發現緩慢、排查步驟不清、備件不可用、文檔不足、設備訪問困難,或缺少受過訓練的人員。
理解修復週期可以幫助團隊改善停機背後的真實原因,而不是只盯着最終數字本身。
故障檢測與報告
修復週期從故障被檢測到時開始。在某些系統中,檢測可以通過報警、傳感器、監控看板、自診斷或故障代碼自動完成。在其他情況下,操作員、用戶或技術人員發現問題後再進行人工報告。
快速檢測能夠降低故障的整體影響。如果機器故障被立即發現,維修就可以在問題擴散到生產質量、安全或下游設備之前開始。在 IT 和網絡運維中,自動告警可以顯著縮短事件響應時間。
診斷與根因識別
故障發現之後,技術人員或工程師必須識別原因。診斷可能包括目視檢查、日誌分析、電氣測試、機械檢查、軟體審查、網絡跟蹤,或與歷史故障記錄進行對比。
診斷往往是影響 MTTR 的關鍵因素之一。擁有良好文檔、清晰故障代碼、遠程監控和有經驗技術人員的團隊,通常能比只依賴試錯的團隊更快定位問題。
修復、更換與驗證
實際修復可能涉及部件更換、軟體重啟、配置修正、線纜修理、機械調整、韌體恢復、清潔、潤滑、重新校準或整機更換。
修復完成後,系統應在恢復正常使用前進行測試。驗證可能包括啟動測試、安全檢查、生產試運行、網絡連通性測試、報警復位確認或用戶驗收。如果缺少驗證,系統可能看似已經修好,但很快又再次故障。
為什麼這個指標很重要
MTTR 之所以重要,是因為停機會帶來真實後果。它可能停止生產、延遲服務交付、降低客戶滿意度、增加運營成本、帶來安全風險,並破壞業務連續性。通過跟蹤修復時間,組織可以發現維護中的薄弱環節並提升恢復表現。
MTTR 在能夠推動行動時最有價值。目標不只是計算平均修復時間,而是理解維修為什麼會花這麼久,以及流程如何改進。
降低停機影響
較低的 MTTR 意味著設備或系統在故障後能更快恢復運作。在製造業中,這可以減少生產損失。在通信和 IT 環境中,它可以降低服務中斷。在樓宇和基礎設施中,它可以提升舒適性、安全性和服務可用性。
對關鍵任務系統而言,減少停機尤為重要。應急通信平台、配電設備、醫療系統、交通控制基礎設施、安防系統和工業生產線通常都要求快速恢復,因為服務中斷可能造成嚴重的運營後果。
提升維護效率
MTTR 為維護團隊提供了一種評估問題響應效率的方法。如果平均修復時間在上升,管理人員可以調查原因是否來自備件延遲、培訓不足、設備訪問困難、升級流程緩慢或維修說明不清。
通過按設備類型、地點、班次或服務團隊比較 MTTR,組織可以識別最需要改進的環節。這有助於更合理地配置人員、開展有針對性的培訓、完善文檔,並制定更智能的備件計劃。
支持可靠性和可用性目標
系統可用性取決於故障頻率和恢復速度。即使設備偶爾發生故障,快速維修也能幫助保持可接受的服務可用性。因此,MTTR 常與平均故障間隔時間、正常運作時間百分比、服務級別目標和可靠性目標一起使用。
例如,一個頻繁故障且修復時間很長的系統,可用性會很差。一個故障較少且修復很快的系統,從運營連續性的角度看通常表現更好。
對運營和維護團隊的價值
MTTR 的實用價值在於它把技術維護表現與業務結果聯系起來。它幫助團隊從被動維修轉向結構化改進。管理人員不必只笼統討論停機問題,而可以利用修復時間數據做出決策。
更好的備件計劃
如果維修時間過長是因為備件不可用,MTTR 數據可以暴露這一問題。維護團隊隨後可以識別關鍵部件、設定最低庫存水平、改進供應商協議,或使用替換模組來加快恢復。
對高價值或安全相關資產而言,保留備件庫存的成本可能遠低於長時間停機的成本。MTTR 分析可以用可量化證據支持這一決策。
更清晰的服務級別管理
在外包維護、IT 支持、通信服務和設施運營中,MTTR 可以支撐服務級別協議。它為服務提供方和客戶提供了一個可衡量的維修績效指標。
不過,服務級別目標應當現實。簡單門禁讀卡器的維修目標,與複雜生產線、大型 HVAC 系統或多站點網絡故障的目標並不相同。設備複雜度、位置、風險等級和訪問條件都應納入考慮。
更有效的培訓和文檔
較高的 MTTR 可能說明技術人員需要更好的培訓或更清晰的維修說明。如果同一類故障反覆需要很長時間才能解決,組織可以建立標準化排障指南、可視化作業說明、診斷清單或遠程支持流程。
良好的文檔可以減少對個人經驗的依賴,也能幫助新技術人員更有信心地完成維修,並降低重複錯誤的風險。
跨行業的常見應用
Mean Time to Repair 被許多行業采用,因為幾乎每個組織都依賴可能發生故障的資產、系統、設備或服務。具體維修流程可能不同,但衡量和改善恢復時間的需求是普遍存在的。
制造與工業設備
在制造工廠中,MTTR 用於衡量生產線、電機、泵、輸送機、機器人、數控機床、包裝設備、傳感器、控制櫃和公用系統的維修表現。
在工業環境中降低 MTTR 可以改善生產連續性、減少加班、提高資產利用率,並支持精益維護計劃。它還幫助維護團隊識別哪些機器帶來了最大的維修負擔。
IT 系統與數據中心
在 IT 運維中,MTTR 可用於伺服器、儲存系統、應用程序、資料庫、雲服務、防火牆、交換機、路由器和面向用戶的平台。它常用於事件管理和站點可靠性工程。
對數字服務而言,修復可能是恢復軟體功能,而不是更換實體部件。修復過程可能包括日誌審查、回滚、打補丁、故障切換、配置修正、重啟或從備份恢復。
通信與網絡基礎設施
通信運營商和企業網絡團隊使用 MTTR 評估基站、光纖鏈路、傳輸設備、IP 網絡、通信網關、路由器、交換機和服務平台的恢復速度。
網絡故障可能一次影響大量用戶。快速修復和準確故障定位對於維持服務質量至關重要。遠程監控、冗餘鏈路、清晰的升級路徑和現場服務協調都可以幫助降低 MTTR。
設施、樓宇和公用系統
設施管理人員使用 MTTR 管理 HVAC 系統、電梯、泵、照明控制、門禁控制、火災報警接口、安防設備、配電系統、供水系統和樓宇自動化設備。
在樓宇和公用事業環境中,MTTR 與人員舒適性、安全、法規合規和服務連續性密切相關。較長的維修時間會影響租戶、訪客、生產區域或公共基礎設施用戶。
MTTR 與相關指標的比較
MTTR 經常與其他可靠性和維護指標一起討論。理解它們之間的差異,可以幫助團隊為不同目的選擇合適的指標。MTTR 關注修復速度,而其他指標可能關注故障頻率、服務可用性或事件響應時間。
| 指標 | 含義 | 主要用途 |
|---|---|---|
| MTTR | 平均修復時間 | 衡量恢復故障資產或系統所需的平均時間 |
| MTBF | 平均故障間隔時間 | 衡量兩次故障之間的平均運作時間 |
| MTTF | 平均失效時間 | 估算不可維修項目在失效前的預期壽命 |
| MTTA | 平均確認時間 | 衡量發現並確認一個事件所需的時間 |
| Availability | 運作可用率 | 顯示系統可供使用的頻率 |
MTTR 與 MTBF
MTBF 衡量故障發生的頻率,而 MTTR 衡量故障被修復的速度。兩者都很重要。一個系統可能具有較高的 MTBF,但如果每次維修都需要很長時間,仍然會造成嚴重中斷。
例如,一臺機器一年只故障兩次,但如果每次都要維修三天,仍然可能成為問題。另一方面,某個不太關鍵的設備可能故障更頻繁,但幾分鐘內就能修好。要獲得完整的可靠性視圖,應把 MTBF 和 MTTR 放在一起審視。
MTTR 與可用性
可用性受到 MTTR 的強烈影響。在故障率不變的前提下,如果修復時間縮短,可用性就可能提高。這就是為什麼對於暫時無法重新設計以減少故障的系統,降低 MTTR 是一種常見策略。
在實際工作中,團隊可以通過預防故障、更快維修、增加冗餘、改進監控,或設计在維修期間仍能以降級模式運作的系統來提高可用性。
如何縮短修復時間
降低 MTTR 並不只是要求技術人員更快工作。可持續的改進通常來自更好的系統設计、更好的資訊、更充分的準備和更顺畅的協調。目標是消除修復流程中的延誤。
使用監控和早期故障檢測
自動監控可以在異常發展成重大故障之前發現問題。傳感器、日誌、告警、儀表盘、狀態監測系統和預測性維護工具,可以幫助團隊更早響應並更快診斷問題。
當設備出現振動、溫升、壓力變化、電壓波動、錯誤代碼或通信不穩定等預警信號時,早期檢測尤其有價值。及時處理這些信號可以同時減少維修時間和故障影響。
標準化故障排查流程
當技術人員按照清晰流程操作時,維修速度會提高。故障排查清單、故障樹、維護手冊、接線圖、備件清單、軟體恢復步驟和升級規則都可以減少不確定性。
標準流程還可以讓不同技術人員和不同班次之間的表現更加一致,確保同一個問題每次都以同樣可靠的方式處理。
改善備件和工具獲取
很多維修延誤並不是因為故障很難,而是因為所需部件、工具、密碼、軟體映像、線纜或測試儀器不可用。準備維修包並儲備關鍵備件,可以顯著縮短恢復時間。
對於分散式站點,本地備件、區域服務中心或模組化替換策略可以避免長時間的路途和運輸延遲。在數字系統中,可直接使用的備份和配置範本可以發揮類似作用。
MTTR 的局限和誤用
盡管 MTTR 很有用,但不應把它當作唯一的維護績效指標。低 MTTR 並不總是表示系統可靠,它可能只是說明團隊擅長修復反覆出現的故障。如果同一資產持續故障,根本問題仍然需要處理。
MTTR 也可能掩盖差異。平均值看起來可以接受,但少數關鍵事件的修復時間可能遠超預期。對於重要系統,團隊應分別審視修復時間分佈、最嚴重事件、重複故障和高風險設備。
不要忽視故障預防
修復速度很重要,但預防可避免的故障通常更好。預防性維護、狀態監測、設计改進、正確安裝、操作員培訓和環境保護都可以降低故障頻率。
強有力的維護策略應在快速修復和長期可靠性提升之間保持平衡。MTTR 告訴團隊恢復得有多快,但如果不結合根因分析,它無法解釋故障為什麼最初會發生。
不要脱離背景進行比較
在不同系統之間比較 MTTR 可能產生誤導。簡單的傳感器更換,不能與渦輪維修、網絡中斷、電梯故障或資料庫恢復相提並論。每類資產都有自己的複雜度、風險等級、訪問條件和維修要求。
有意義的比較應在相似設備組、相似服務條件或同一資產的長期表現之間進行。這樣團隊才能識別真正的改進,而不是制造不公平的績效判斷。
實際使用中的最佳實践
要有效使用 MTTR,組織應清晰定義指標、採集可靠數據、分析長時間維修背後的原因,並把發現轉化為改進行動。這個指標應支持更好的決策,而不是只成為報表上的數字。
定義開始點和結束點
每個組織都應決定修復時間從何時開始、到何時結束。它可以從故障被報告、工單被打開、技術人員到達,或主動維修開始時計算;也可以在資產重啟、測試完成或用戶確認服務恢復時結束。
所選擇的定義應與測量目的一致。如果目標是改善客戶服務,總停機時間可能更相關。如果目標是評估技術人員維修效率,主動維修時間可能更合適。
對數據進行分段
團隊不應為所有資產只計算一個笼統的 MTTR,而應按設備類型、地點、故障類別、嚴重級別、團隊、班次、供應商或系統功能對數據進行分段。這會讓指標更有用,也更容易轉化為行動。
例如,某個設施可能發現泵的維修很快,但電梯維修較慢,因為備件依賴外包。IT 團隊可能發現應用事件解決很快,而網絡事件需要更長診斷時間。數據分段可以揭示改進應從哪裡開始。
將 MTTR 與根因分析結合
當修復時間較長時,團隊應調查原因。故障是否難以診斷?文檔是否缺失?備件是否不可用?審批是否延遲?遠程訪問是否不可用?設備是否難以到達?
根因分析可以把 MTTR 從被動測量變成主動改進工具。長期來看,這可以減少停機、提升可靠性,並讓維護計劃更可預測。
FAQ
Mean Time to Repair 是什麼意思?
Mean Time to Repair 是將故障資產、系統、設備或服務恢復到正常運作狀態所需的平均時間。它通過在定義週期內用總修復時間除以修復事件數量來計算。
MTTR 和停機時間一樣嗎?
不一定。MTTR 通常關注維修持續時間,而停機時間可能包括檢測時間、報告延遲、等待時間、備件延遲、審批時間和重啟時間。組織在使用该指標前,應明確包含哪些內容。
什麼樣的 MTTR 數值算好?
良好的 MTTR 取決於設備、行業、服務要求和故障嚴重程度。數字服務重啟可能期望幾分鐘完成,而複雜工業設備需要數小時也可能合理。最好的基準通常是與類似資產或以往表現對比。
企業如何降低 MTTR?
企業可以通過改進監控、加快故障檢測、標準化排障流程、培訓技術人員、保持關鍵備件可用、使用遠程診斷、完善文檔和簡化設備訪問來降低 MTTR。
為什麼 MTTR 對可靠性很重要?
MTTR 很重要,因為維修速度直接影響停機時間和系統可用性。即使可靠的系統也會發生故障,因此快速恢復有助於降低運營影響、服務中斷、生產損失和客戶不滿。
MTTR 和 MTBF 有什麼區別?
MTTR 衡量故障後的修復耗時,MTBF 衡量兩次故障之間的平均時間。MTTR 關注恢復速度,MTBF 關注故障頻率。兩項指標都有助於理解整體可靠性和可用性。







