

在發生故障時保持服務運行
故障轉移是一種系統可靠性機制,可以在主組件發生故障時,自動或手動將執行任務從主組件切換到備用組件。它常用於應用程式、網路、伺服器、資料庫、通訊系統、雲端服務和工業平台,在硬體、軟體、鏈路或服務停止工作時保持系統可用。
簡單來說,故障轉移回答了一個關鍵問題:如果主系統失敗,誰來接管?設計良好的故障轉移架構可以減少停機時間,保護服務連續性,並協助組織更快地從故障、過載、維護事件或意外中斷中恢復。
故障轉移不能阻止所有故障發生。它的價值在於,當故障出現時,為系統提供一條已經準備好的恢復路徑。
基本含義與系統角色
故障轉移通常用於高可用性設計。主資源負責正常執行,一個或多個備用資源保持就緒狀態,當主資源不可用時接管服務。備用資源可以是另一台伺服器、路由器、資料庫節點、網路鏈路、資料中心、雲端區域、儲存系統或應用實例。
其目標是減少服務中斷。系統不需要等技術人員先修復故障組件再恢復服務,而是將流量、工作負載、工作階段或請求重新導向到另一個可用資源。
主資源與備用資源
主資源是正常提供服務的活動組件。備用資源則在主資源發生故障時接管服務。在一些系統中,備用資源處於被動狀態,等待故障轉移觸發;在另一些系統中,多個資源會同時主動分擔流量。
例如,一個網站可以執行在兩台應用伺服器上。如果第一台伺服器失敗,流量可以發送到第二台伺服器。路由器在主互聯網連線中斷時可以使用備用 WAN 鏈路。資料庫在原主節點失敗時,可以將副本提升為新的主節點。
故障偵測
故障轉移依賴故障偵測。系統必须知道主組件何時處於不健康狀態。偵測方式可以包括心跳訊號、健康檢查、鏈路監控、服務探測、資料庫複製狀態、應用回應檢查或網路可達性測試。
良好的偵測既要足夠快,以減少停機時間,又不能過於敏感,避免因短暫延遲或臨時封包遺失觸發不必要的故障轉移。這種平衡在實際網路和應用設計中非常重要。
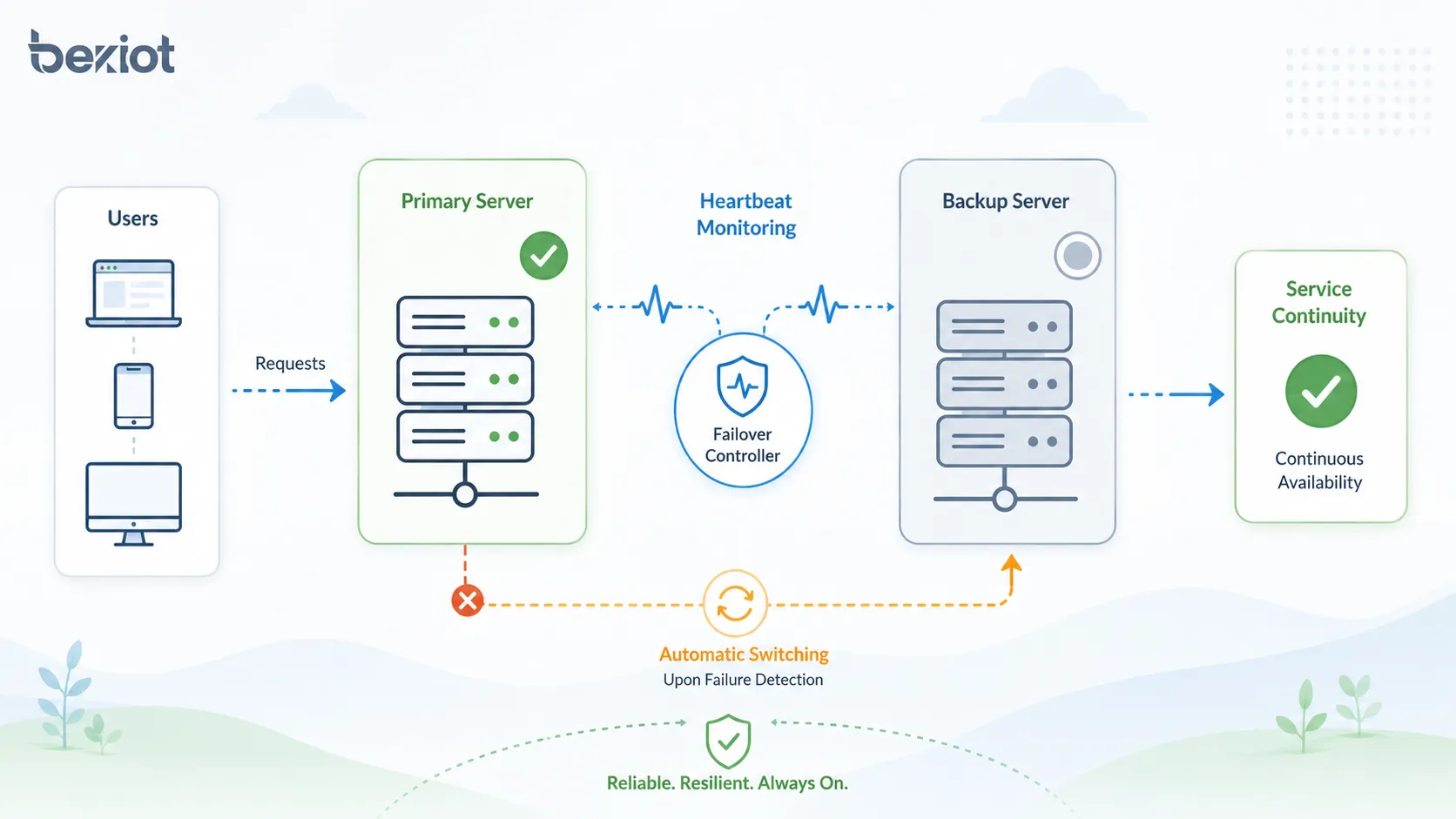
故障轉移流程如何工作
故障轉移流程通常包括監控、故障偵測、決策判斷、服務切換、流量重新導向、恢復驗證和事件記錄。不同系統的细节會有所不同,但核心逻輯相似。
當監控機制偵測到主系統不可用或不健康時,故障轉移控制器會觸發備用路徑。使用者可能會感受到短暫中斷,但服務應通過備用組件繼續執行。
監控與健康檢查
健康檢查用於確認服務是否正常執行。基礎健康檢查可能只測試伺服器是否回應 ping。更進階的健康檢查則會驗證應用是否能夠處理請求、連線資料庫並返回有效回應。
應用層健康檢查通常比簡單的網路檢查更可靠。伺服器可能仍能回應 ping,但執行在其上的應用已經凍结、過載或無法存取所需的後端服務。
切換到備用資源
確認故障後,系統會將執行切換到備用資源。這可能涉及修改路由表、更新 DNS 記錄、遷移虛擬 IP 位址、提升資料庫副本、激活備用伺服器,或通過負載平衡器重新導向流量。
切換方式應與業務要求匹配。有些系統可以接受几分鐘中斷,而關鍵系統可能需要接近即時的故障轉移,並尽量降低對使用者的影響。
切換後的服務驗證
故障轉移完成後,應驗證備用服務。系統需要確認使用者可以連線、交易可以繼續、數據可用,並且相依性服務執行正常。
驗證非常重要,因為把流量切換到備用組件並不自動意味着服務一定正常。備用資源必须正確同步、設定無誤,並具備承載工作負載的能力。
故障轉移的主要類型
故障轉移可以根據系統關鍵性、預算、效能要求和恢復目標采用不同設計。常見模式包括主動-被動、主動-主動、手動故障轉移、自動故障轉移、本地故障轉移和地理故障轉移。
主動-被動故障轉移
在主動-被動故障轉移中,一個系統主動處理生產流量,另一個系統處於備用模式。如果主動系統失敗,被動系統會變為活動狀態並接管服務。
這種模式相對簡單,廣泛用於伺服器、防火牆、資料庫、PBX 系統、儲存控制器和網路閘道。它的主要優勢是角色分离清晰,限制是備用資源在正常執行期間可能使用率較低。
主動-主動故障轉移
在主動-主動故障轉移中,兩個或多個系統同時處理流量。如果一個系統失敗,其餘系統繼續為使用者提供服務並承担额外負載。
這種模式可以提高資源使用率和擴展性,但需要更谨慎的設計。負載均衡、數據同步、工作階段處理、衝突控制和容量規劃都會變得更加復雜。
手動與自動故障轉移
手動故障轉移需要操作員或管理員觸發切換。它提供人工控制,适用於維護、計畫遷移或敏感系統變更。
自動故障轉移由系統規則觸發。它速度更快,更适合高可用環境,但必须谨慎設定,以避免誤切換、腦裂狀態或節點之間反復切換。
本地與地理故障轉移
本地故障轉移發生在同一站點、機架、資料中心或網路區域內,用於防護本地伺服器、鏈路、電源模組或設備故障。
地理故障轉移會將服務切換到另一個資料中心、雲端區域或遠端站點。它用於應對更大範圍的故障,例如資料中心中斷、區域網路故障、停電、火灾、洪水或重大基礎設施事件。
可靠設計的關鍵特性
良好的故障轉移系統不應只是切換速度快,还應安全、一致、可預測。最重要的特性包括監控、冗餘、同步、流量控制、日誌記錄和恢復規劃。
冗餘組件
冗餘意味着在故障發生之前就準備好備用組件。這些組件可以包括伺服器、電源、網路鏈路、路由器、交換器、儲存路徑、資料庫、應用實例和雲端區域。
冗餘必须具有實際意義。如果備用伺服器連線到同一個已經失效的電源或同一個單點交換器,就不能提供真正的韌性。設計人員應避免隐藏的單點故障。
心跳與狀態監控
心跳訊號協助系統檢查主節點是否仍然存活。如果備用節點在規定時間內停止接收心跳訊息,它可能會判斷主節點已經失敗。
心跳設計應考慮網路延遲、封包遺失和管理鏈路可靠性。設定不當的心跳會導致腦裂問題,即兩個節點都認為自己應該處於活動狀態。
數據同步
許多故障轉移系統需要在主節點和備用節點之間同步數據。這可能涉及資料庫複製、檔案同步、儲存鏡像、設定備份或狀態共享。
同步會影響恢復質量。如果備用端數據過舊,故障轉移可能恢復服務却丟失最近交易。如果同步太慢,恢復点目標可能無法满足。
自動流量重新導向
流量重新導向让使用者或系統在故障轉移後能夠存取備用服務。實現方式可以包括負載平衡器、虛擬 IP 位址、路由協议、DNS 故障轉移、SD-WAN 策略或應用閘道。
重新導向方式應與預期恢復時間匹配。基於 DNS 的故障轉移較簡單,但可能因快取而較慢。負載平衡器或虛擬 IP 故障轉移在本地高可用環境中通常更快。
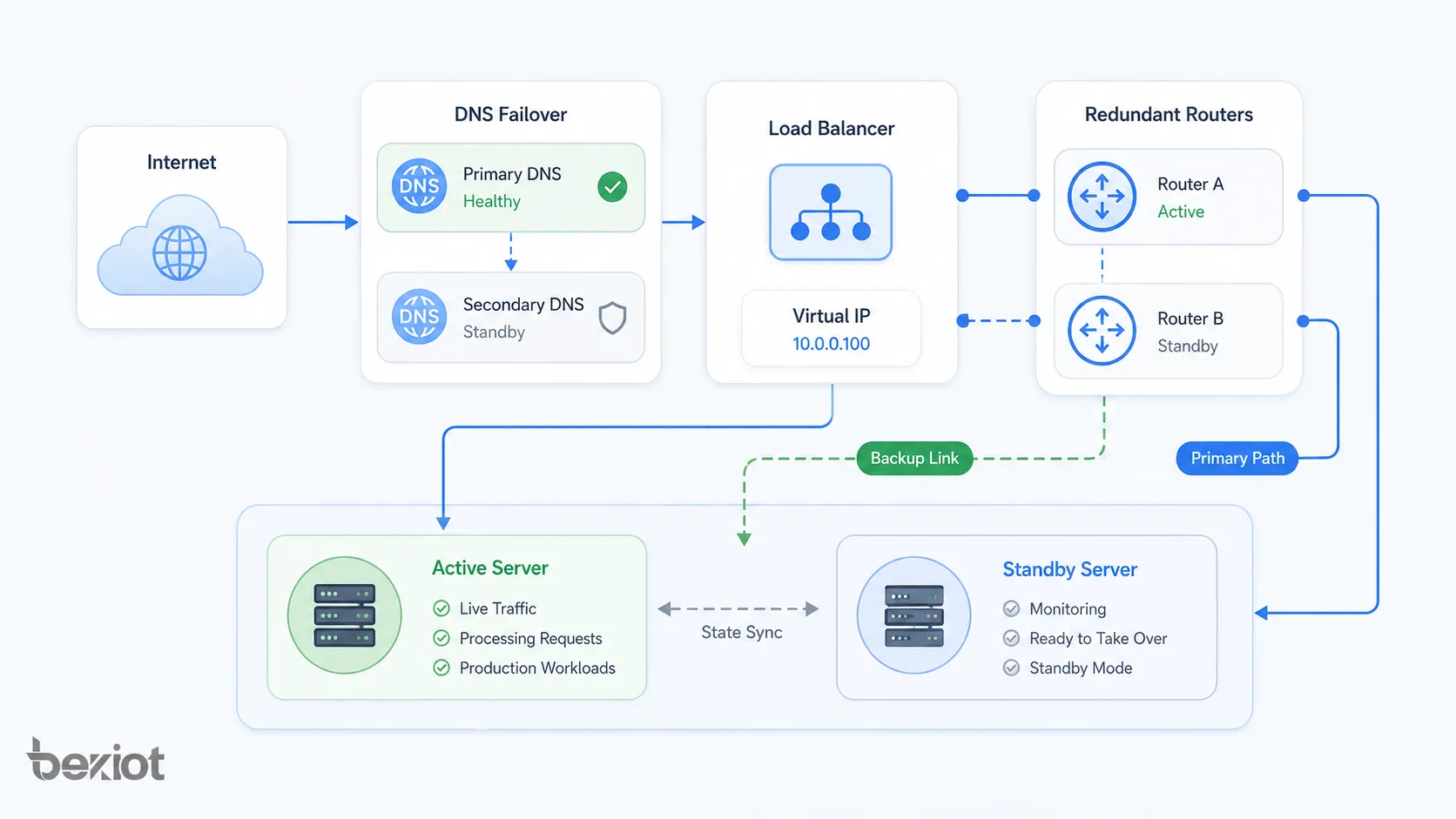
網路架構模式
故障轉移架構可以應用在網路和系統栈的不同層級。它可以保護實體鏈路、路由路徑、伺服器叢集、資料庫、雲端區域或應用服務。
伺服器級故障轉移
伺服器級故障轉移使用兩台或多台伺服器提供同一服務。如果一台伺服器失敗,另一台伺服器接管。這常見於應用伺服器、Web 伺服器、檔案伺服器、通訊伺服器和管理平台。
伺服器級故障轉移可以使用叢集軟體、虛擬化平台、負載平衡器、容器編排或高可用服務。伺服器之間的設定一致性非常關鍵。
網路鏈路故障轉移
網路鏈路故障轉移在主連線失敗時使用備用網路路徑。範例包括双 WAN、備用光纖鏈路、LTE 或 5G 備份、冗餘 ISP 連線以及 SD-WAN 鏈路切換。
這對分支机構、遠端站點、零售連锁、工業設施和云連線系統很重要。如果主鏈路失敗,備用鏈路可保持通訊可用,尽管頻寬或延遲可能發生變化。
路由器與防火牆故障轉移
路由器和防火牆通常支持高可用成對部署。一個設備可以處於活動狀態,另一個處於備用狀態,也可以根據設計共同分擔負載。通常會使用虛擬閘道位址,使用戶端無需知道哪台實體設備處於活動狀態。
防火牆故障轉移應尽可能同步工作階段狀態。如果没有工作階段同步,即使新連線可以正常繼續,現有連線也可能在故障轉移流程中中斷。
資料庫故障轉移
資料庫故障轉移通過從失敗的主資料庫切換到副本或備用資料庫来保護數據服務。它用於企业應用、電子商務平台、金融系統、雲端服務和關鍵營運平台。
資料庫故障轉移需要谨慎處理複製延遲、事務一致性、寫入衝突和應用重新連線。設計不當的資料庫故障轉移可能導致數據丟失或應用錯誤。
云與多區域故障轉移
云故障轉移可以在可用區、區域或雲端服務商之間切換服務。它用於防護本地基礎設施故障,並支持災難復原策略。
多區域故障轉移可能需要全域流量管理、複製資料庫、物件儲存同步、身份服務可用性以及經過驗證的恢復流程。設計應匹配恢復時間目標和恢復点目標。
故障轉移指標與規劃目標
故障轉移規劃通常由可用性和恢復指標指導。這些指標協助組織決定需要多少冗餘,以及可以接受多少停機時間或數據損失。
| 指標 | 含義 | 重要性 |
|---|---|---|
| RTO | 恢復時間目標 | 故障後恢復服務的最大可接受時間 |
| RPO | 恢復点目標 | 按時間衡量的最大可接受數據丟失量 |
| MTTR | 平均修復時間 | 恢復故障組件所需的平均時間 |
| MTBF | 平均故障間隔時間 | 兩次故障之間的平均執行時間 |
| 可用性 | 服務處於執行狀態的時間百分比 | 體現服務整體線上表現 |
恢復時間目標
恢復時間目標定義了服務在故障後必须多快恢復。非關鍵的內部報表工具可能可以接受數小時停機,而支付系統、應急平台或生產控制系統可能要求在數秒或數分鐘內恢復。
更低的 RTO 通常需要在自動化、冗餘、監控和基礎設施上投入更多。設計應匹配業務影響,而不是假設每個系統都需要同等保護層級。
恢復点目標
恢復点目標定義了可以接受多少數據丟失。如果組織只能接受几秒鐘的數據丟失,就可能需要近實時複製;如果可以接受數小時,定期備份可能已經足夠。
RPO 對資料庫、檔案系統、交易平台、客戶記錄和營運日誌尤其重要。没有數據規劃的故障轉移可能恢復服務,但仍造成不可接受的業務損失。
對業務和營運的價值
故障轉移有價值,是因為停機時間會影響收入、安全、生產力、客戶信任和營運連續性。設計良好的故障轉移策略協助組織在意外故障和計畫維護期間保持服務。
更高的服務可用性
主要效益是提高可用性。當主組件失敗時,備用組件繼續服務。這減少停機時間,並協助使用者保持工作。
高可用性對線上服務、通訊系統、醫療平台、交通網路、工業自動化、金融系統和面向公眾的應用都很重要。
降低營運風險
故障轉移降低了單個組件故障導致整個系統停止的風險。這對於存在單點故障的系統尤其重要,例如單一互聯網鏈路、單台伺服器、單個資料庫或單個閘道。
通過增加備用路徑和自動恢復逻輯,組織可以降低硬體故障、網路中斷、軟體崩潰和維護中斷的影響。
更灵活的維護
故障轉移可以支持計畫維護。管理員可以將服務從一個節點移動到另一個節點,更新主系統,測試變更,然後在工作完成後切換回来。
這減少了對长時間維護視窗的需求,也让升級更安全,因為服務可以通過備用資源保持可用。
提升使用者信任
使用者可能看不到故障轉移流程,但會感知服務是否持續可用。可靠系統可以提升客戶信任、員工效率以及對數位基礎設施的信心。
對關鍵通訊、工業和業務平台而言,可用性不仅是技術指標,也是服務體驗的一部分。
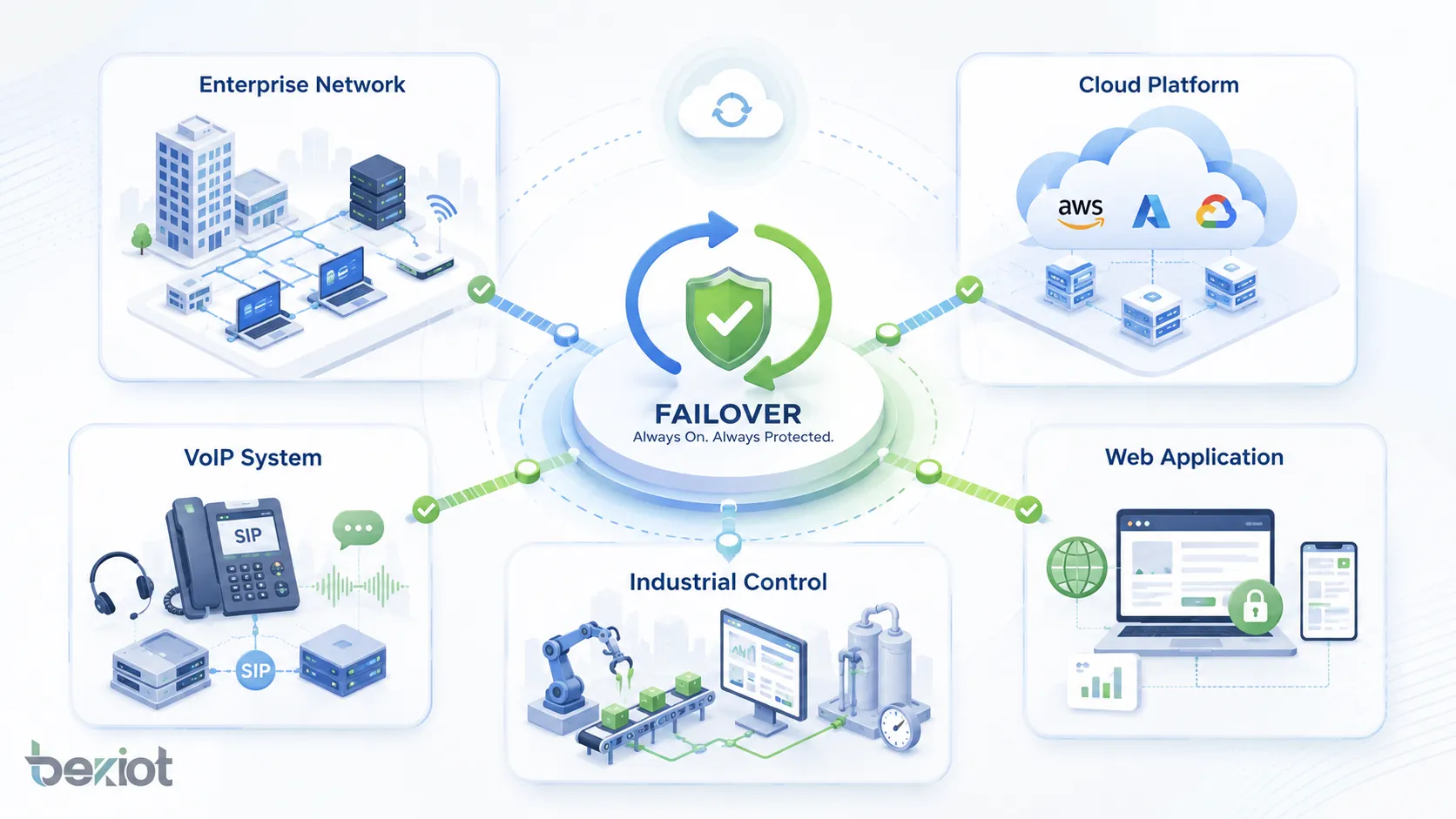
不同系統中的應用
凡是需要連續性的地方,都可以使用故障轉移。具體設計取決於系統類型,但目標始終一致:在故障發生時避免服務中斷。
企业網路
企业網路將故障轉移用於互聯網鏈路、防火牆、路由器、交換器、VPN 通道、無線控制器和分支机構連線。如果一條路徑失敗,流量可以轉移到另一條路徑。
在多分支組織中,故障轉移協助遠端辦公室保持與雲端服務、資料中心、通訊系統和業務應用的連線。
資料中心與云平台
資料中心將故障轉移用於伺服器、儲存、資料庫、虛擬化叢集、電力系統、冷却系統和網路結構。云平台使用可用區、區域故障轉移、負載平衡器、自動擴展组和託管資料庫副本。
如果規劃得當,這些設計可以協助應用在硬體故障、主机故障、機架故障甚至區域服務中斷時繼續執行。
VoIP 與通訊系統
VoIP 和 SIP 系統可以將故障轉移用於 SIP 伺服器、PBX 平台、閘道、SBC、SIP 中繼、DNS SRV 記錄、媒體伺服器和網路鏈路。如果一個伺服器或中繼失敗,通話可以通過備用路徑路由。
這對企业通訊很重要,因為語音服務失敗會影響客戶聯系、內部協作、緊急通話和服務營運。
工業與營運技術
工業環境可以將故障轉移用於 SCADA 伺服器、控制網路、監控平台、HMI 站點、歷史資料庫、工業閘道和通訊鏈路。目標是保持生產、監控以及安全相關操作可用。
工業故障轉移設計必须考慮確定性通訊、設備相容性、環境條件和安全操作流程。自動切換不應造成不安全的机器行為。
Web 應用與線上服務
Web 應用通過負載平衡器、複製的應用伺服器、資料庫副本、CDN 服務、DNS 故障轉移和多區域部署實現故障轉移。這些方法協助網站和 API 在伺服器或網路故障期間保持可用。
對電子商務、銀行、SaaS、流媒體和客戶门戶而言,故障轉移可以在意外中斷期間保護收入和使用者體驗。
常見挑战與風險
故障轉移可以提升韌性,但設計不當也會带来新問題。備用系統必须經過測試、更新、同步並具備合适容量。否則,它可能在最需要的時候無法發揮作用。
誤故障轉移
誤故障轉移是指主服務並未真正失敗,系統却切換到了備用端。這可能由臨時封包遺失、回應緩慢、監控過載或過於激進的閾值造成。
誤故障轉移會给使用者带来不必要的中斷。健康檢查應設計為先確認真實服務故障,再执行切換。
腦裂狀態
腦裂狀態是指兩個節點都認為自己是活動主節點。當心跳通訊失敗但兩個系統仍在執行時,可能發生這種情況。
在資料庫、儲存和叢集系統中,腦裂很危險,因為它可能導致數據損壞或寫入衝突。仲裁機制、隔離措施和正確的叢集設計有助於降低這種風險。
備用容量不足
備用資源必须有足夠容量在故障轉移後承載工作負載。如果備用資源太小,服務可能在技術上仍線上,但效能很差。
容量規劃應考慮尖峰負載、增长、降級模式執行,以及多個故障同時發生的可能性。
未經測試的恢復計畫
從未測試過的故障轉移設計並不可靠。設定漂移、過期憑證、舊備份、防火牆變更、DNS 快取、缺失授權或舊軟體版本,都可能阻止成功恢復。
定期故障轉移演練是必要的。測試應尽可能包括計畫故障轉移和非計畫故障情境。
可靠部署的最佳實務
故障轉移應作為更廣泛的高可用和災難復原策略的一部分来設計。它應包括架構規劃、監控、檔案、測試和持續改善。
先識別關鍵服務
並非每個系統都需要同樣層級的故障轉移。組織應識別哪些服務是關鍵服務、停機如何影響營運,以及需要什麼恢復目標。
這有助於確定投資優先順序。關鍵系統可能需要自動故障轉移和地理冗餘,而較低關鍵性的系統可能只需要備份和手動恢復。
消除隐藏的單點故障
隐藏相依性會削弱故障轉移能力。備用伺服器可能相依性與主伺服器相同的儲存、電源、網路交換器、DNS 服務或驗證系統。
架構審查應識別這些相依性。真正的韌性要求在完整服務路徑上實現冗餘,而不仅仅是可見的應用層。
保持設定同步
主系統和備用系統應使用一致的設定。軟體版本、防火牆規則、憑證、路由策略、使用者數據或應用設置上的差異,都可能導致故障轉移失敗。
設定管理工具、模板、備份和變更控制有助於保持系統一致。每次重大變更後,都應重新檢查故障轉移準備情況。
定期測試故障轉移
定期測試可以確認故障轉移在真實條件下是否有效。測試應驗證偵測時間、切換時間、數據一致性、應用行為、使用者存取、日誌記錄和回切流程。
測試應形成檔案。每次測試都應記錄測試內容、發生情況、失敗点以及需要改善的事項。
故障轉移後的回切與恢復
故障轉移只是恢復流程的一部分。主系統修復後,組織必须決定是否以及如何將服務迁回。這個流程称為回切。
何時回切
回切不應過快進行。原主系統應在完全修復、測試、同步和驗證之後,再將流量迁回。如果回切過急,系統可能再次失敗並造成新的中斷。
一些組織會選擇让備用系統保持活動狀態,直到下一個維護視窗。這樣可以實現受控回归,而不是立即切換。
數據與狀態同步
在回切之前,備用執行期間產生的數據必须同步回原主系統。這對資料庫、檔案、交易、使用者工作階段和設定變更尤其重要。
没有适當同步,回切可能導致數據丟失、記錄過舊或服務行為不一致。
事件後檢討
故障轉移事件之後,团队應檢討發生了什麼。檢討應包括故障原因、偵測時間、切換结果、使用者影響、備用效能、溝通流程和改善措施。
這樣可以把故障轉移從一次性的恢復事件,轉化為持續提升可靠性的流程。
FAQ
什麼是故障轉移?
故障轉移是一種可靠性機制,可以將服務、流量、工作負載或操作從失敗的主組件切換到備用組件。它用於減少停機時間並保持服務連續性。
故障轉移和備份有什麼差異?
備份用於儲存數據或設定以便恢復。故障轉移是在故障發生時將活動服務切換到另一個資源。備份協助恢復資訊,而故障轉移協助服務持續執行。
什麼是主動-被動故障轉移?
主動-被動故障轉移使用一個活動系統和一個備用系統。備用系統只有在活動系統失敗或因維護下線時才接管服務。
什麼是主動-主動故障轉移?
主動-主動故障轉移使用多個系統同時處理流量。如果其中一個系統失敗,其餘系統繼續為使用者服務並承担额外工作負載。
故障轉移通常用於哪裡?
故障轉移通常用於企业網路、云平台、資料中心、資料庫、Web 應用、VoIP 系統、防火牆、路由器、儲存系統和工業控制平台。
如何測試故障轉移?
可以通過模擬主系統故障、以受控方式中斷網路路徑、關閉測試節點、觸發維護故障轉移、檢查服務切換、驗證數據一致性,並在恢復後查看日誌来測試故障轉移。







