系統升級不應該從升級套件本身開始。它應該先從一個簡單的維運問題開始:在變更過程中,哪些內容必須保持穩定?新版本可能帶來安全修補、更好的效能、新功能或更長的支援週期,但也可能引入相容性問題、設定變化、服務中斷和復原壓力。
因此,良好的升級管理並不是在合適時間點擊“更新”這麼簡單,而是用可控的方式管理變更,保護服務、使用者、資料和業務連續性。
從變更原因開始
第一條規則是確認為什麼需要升級。有些升級非常緊急,因為它們修復安全漏洞、嚴重缺陷、合規問題或即將停止支援的風險。有些升級屬於計劃性工作,用於提升效能、增加功能、支援新硬體,或與未來架構保持一致。還有一些升級只是可選項,應等組織具備足夠測試時間後再執行。
如果缺少明確原因,升級決策很容易變成被動反應。團隊可能只是因為有新版本、廠商建議,或其他部門已經升級就跟進操作。這會帶來不必要的風險。一個運行穩定的系統不應隨意改變,除非收益足以抵消可能產生的擾動。
升級目的應使用實際可執行的語言寫清楚。例如“修復認證漏洞”“支援新的資料庫版本”“提升呼叫處理容量”“替換不再支援的作業系統”或“啟用與新平台的整合”。清晰的目的有助於後續界定測試範圍和驗收標準。
當原因清楚後,專案團隊還可以判斷緊急程度。關鍵安全升級可能需要更短的審批週期;功能升級可以安排在低風險維護視窗;重大架構升級則可能需要分階段部署。不同原因對應不同控制等級。
先評估業務影響再採取技術動作
任何升級影響的都不只是技術系統本身。它可能影響使用者、服務視窗、關聯應用、報表、存取權限、終端設備、客戶體驗、生產流程或支援團隊。採取任何技術操作前,團隊應先識別哪些業務流程依賴該系統。
對於持續運行的系統,這一點尤其重要,例如通訊平台、資料庫、工業系統、客戶入口網站、支付系統、監控平台和內部營運工具。即使是短時間中斷,也可能造成漏接電話、交易失敗、生產延誤、記錄不完整或使用者投訴。
業務影響評審應包括尖峰使用時段、關鍵使用者群、外部客戶、內部部門、服務級別承諾以及法律或合規要求。如果系統支撐緊急應變、生產控制、安全監控或公共服務,升級計劃應比一般辦公工具更嚴格。
評審結果應指導排程。有些升級可以在常規維護時間完成,有些需要夜間或週末視窗,有些則需要臨時備用系統、使用者通知或分階段切換。技術上很簡單的升級,如果時間選擇不當,仍然可能存在高風險。
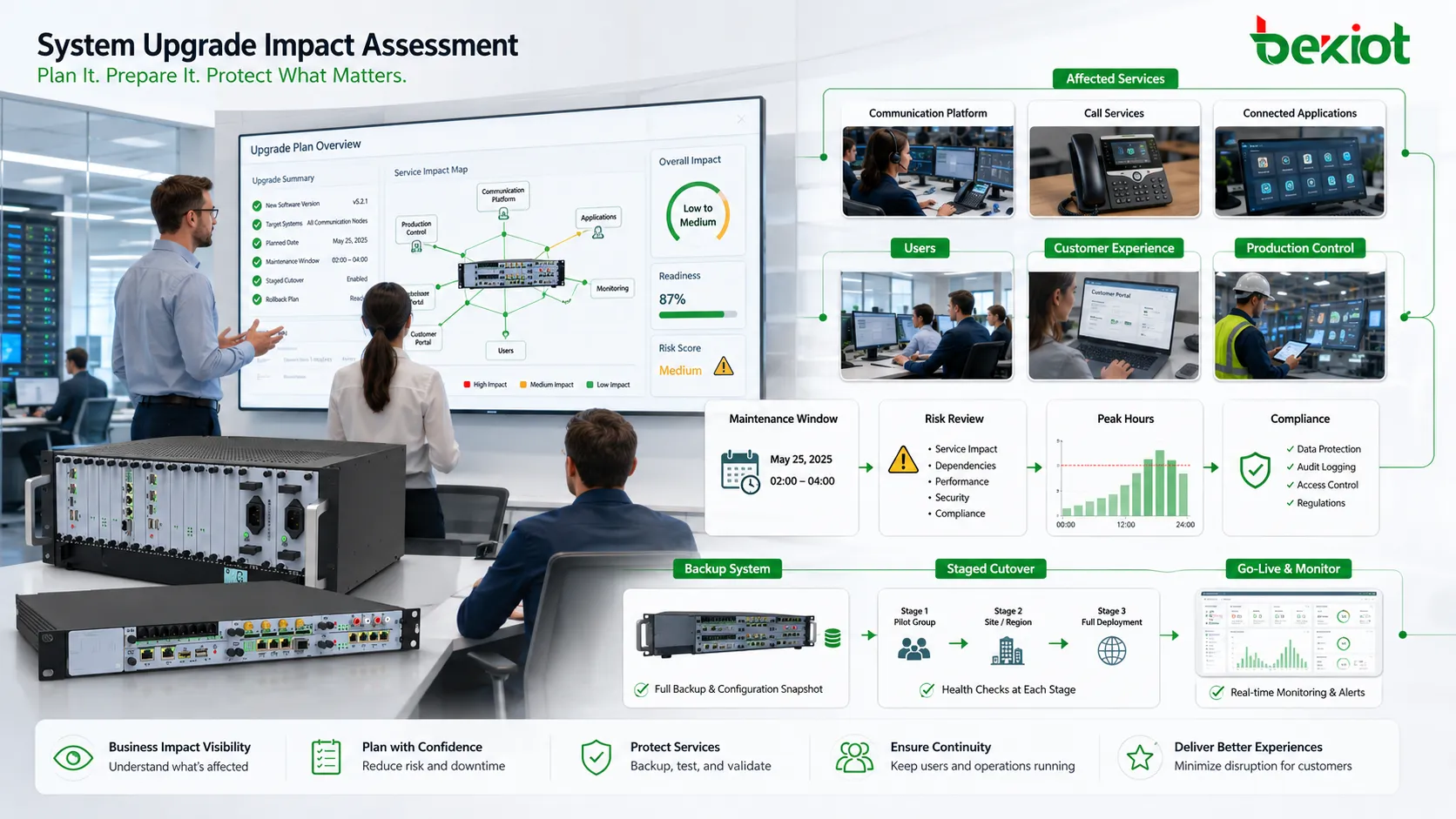
先建立準確的資產清單
如果團隊不知道系統連接了哪些對象,就無法安全升級。資產清單應包括伺服器、作業系統、資料庫、中介軟體、應用、終端、網路設備、儲存、授權、憑證、API、第三方整合、備份工具、監控系統和使用者存取方式。
這份清單能夠暴露隱藏依賴。報表工具可能依賴特定資料庫版本,舊用戶端可能不支援新協定,設備在韌體變更後可能異常,安全系統可能仍使用過時 API。如果這些依賴直到上線後才被發現,回退壓力會顯著增加。
設定清單同樣重要。系統參數、路由規則、使用者權限、整合金鑰、排程任務、服務帳號、防火牆規則、憑證和自訂腳本,都應在升級前記錄。許多升級失敗並不是新版本本身造成的,而是設定細節缺失或被覆蓋。
在大型環境中,清單還應識別不同站點或節點之間的版本差異。某個分支可能運行著不同修補層級,某台伺服器可能有客製化模組,某類設備可能需要專用韌體路徑。這些差異會影響升級順序和測試設計。
確認相容性而不是預設相容
相容性是最常見的升級風險之一。新系統版本可能要求更新的資料庫、不同的執行階段程式庫、升級後的瀏覽器、變更的驅動、修訂後的 API 或新的認證方式。如果關聯系統不相容,升級即使在技術上完成,也可能在業務運行中失敗。
相容性檢查應涵蓋硬體、作業系統、資料庫、應用程式版本、協定、介面、瀏覽器、行動用戶端、終端設備、驅動、外掛、憑證和第三方服務。團隊不應只依賴通用發佈說明,而應把專案現場條件與廠商要求、本機設定逐項比對。
向後相容同樣重要。如果舊用戶端、舊設備或原有整合在升級後仍必須工作,就應直接測試。有些系統允許短期混合版本運行,有些系統則要求所有元件同時升級。對這一點判斷錯誤,可能造成局部服務故障。
當相容性存在不確定性時,應使用試點環境。團隊可以在影響生產前測試代表性設備、使用者角色、資料流和介面呼叫,從而減少在維護視窗內才發現重大衝突的機率。
| 升級區域 | 關鍵規則 | 評審原因 |
|---|---|---|
| 應用程式版本 | 檢查發佈說明和依賴變化 | 防止功能遺失和介面衝突 |
| 資料庫 | 驗證資料表結構、驅動和遷移要求 | 保護資料存取和交易穩定性 |
| 作業系統 | 確認執行階段、服務和安全策略支援 | 避免服務啟動和權限問題 |
| 網路與安全 | 複核防火牆、憑證、DNS 和存取規則 | 防止切換後連線失敗 |
| 終端與用戶端 | 測試代表性使用者設備和版本 | 減少現場相容性投訴 |
改變環境前保護資料
資料保護是不可協商的規則。升級前,團隊應確認備份是否可用、備份是否完整、還原方法是否清楚、儲存位置是否可靠、保留策略是否合理以及還原時間是否可接受。從未驗證過的備份只是一種假設,不是真正的還原方案。
對於資料庫和應用平台,備份應選擇正確時間點。如果升級過程中資料仍在變化,團隊必須決定是停止寫入、使用交易日誌、建立快照,還是準備基於複製的還原。具體方法取決於系統架構和可接受停機時間。
設定備份不能被忽視。應用設定、服務檔案、路由表、排程任務、使用者角色、憑證、金鑰和自訂範本,可能與業務資料同樣重要。升級失敗後,手動重建這些內容可能比復原軟體套件耗時更久。
資料遷移腳本也要仔細審查。有些升級會改變資料表結構、索引、編碼、欄位長度或資料結構,這些變化可能難以逆轉。團隊應提前明確遷移是否可回退、回退是否需要完整還原備份,以及還原大約需要多久。
使用接近真實條件的測試環境
測試環境只有在關鍵方面接近生產環境時才有價值。一個小型空測試系統也許能證明安裝程式可以運行,卻未必能暴露效能問題、資料遷移問題、整合失敗、權限衝突或設備相容性問題。
測試環境應包含有代表性的資料、使用者角色、關聯服務、設定、介面呼叫和典型負載。它不一定要完全複製生產系統,但必須包含足夠真實的因素,才能暴露主要風險。
測試案例應跟隨真實工作流程。根據系統類型,使用者應完成登入、建立記錄、執行報表、發起交易、觸發警報、呼叫 API、產生檔案、存取行動用戶端或使用連接設備等操作。技術啟動成功並不等於服務已經可用。
必要時還應進行效能測試。新版本可能在單使用者場景下正常,但在真實負載下變慢。資料庫遷移、快取行為、記憶體使用、CPU 負載、磁碟 I/O、網路時延和背景任務都應在相關場景中觀察。升級應按運行表現評估,而不是只看安裝是否完成。

部署前準備回退方案
系統升級在考慮回退前不應繼續推進。回退是指在升級失敗或出現不可接受問題時,將系統還原到之前可工作狀態的流程。只說“必要時還原備份”遠遠不夠,團隊必須知道具體如何回退。
回退方案應定義誰有權做出回退決定、哪些條件觸發回退、哪些檔案或資料庫需要還原、還原大約需要多久、可能遺失哪些資料以及如何通知使用者。方案還應說明資料遷移後是否仍可回退,還是只能向前修復。
有些升級容易反向還原,有些升級會改變資料庫結構、加密方式、韌體版本或設定格式,使回退非常困難。這類場景需要格外謹慎,可能需要分階段部署、藍綠架構、備用節點或並行運行來降低風險。
條件允許時,應測試回退流程。沒有演練過的方案在緊急情況下可能失敗。即便只是部分回退演練,也能發現權限缺失、還原速度過慢、備份不完整或職責不清等問題。
控制維護視窗
維護視窗是執行升級的計劃時間段,應根據使用者影響、系統負載、人員可用性、廠商支援、備份完成情況和回退時間來選擇。常見錯誤是視窗只夠執行升級,卻不夠排除故障或回退。
維護視窗應包含準備、最終備份、升級執行、驗證、可能的修復、回退決策時間、回退執行和使用者溝通。如果升級本身只需一小時,但回退需要三小時,視窗就必須反映這一現實。
升級前可能需要凍結變更。其他團隊應避免在同一時段進行無關的設定變更、網路變更、資料庫變更或存取策略變更。多個變更疊加時,故障定位會變得困難。
支援可用性也很重要。關鍵技術人員、應用負責人、網路工程師、資料庫管理員、安全團隊和廠商支援應在視窗內能夠聯絡到。不要把升級安排在唯一了解關鍵依賴的人無法回應的時間。
變更前後與使用者溝通
使用者溝通可以減少混亂。升級前,受影響使用者應知道預計時間、服務影響、臨時限制、聯絡管道,以及在維護視窗內應避免哪些操作。面向公眾的系統還可能需要客戶通知。
溝通內容應具體,但不必堆砌技術細節。使用者需要知道系統是否不可用、是否應停止輸入資料、行動用戶端是否需要更新、密碼或登入方式是否變化,以及服務預計何時恢復。
升級後,使用者應收到系統恢復可用的確認。如果功能發生變化,可能需要發佈簡短說明或使用指引。如果仍有遺留問題,團隊應說明已知限制和預計處理步驟。
良好的溝通可以減少不必要的支援工單。許多升級後的投訴並不是技術故障,而是使用者對介面變化、登入提示、工作階段過期或臨時效能波動感到意外。
通過驗收檢查確認結果
安裝程式結束並不代表升級完成。只有系統通過驗收檢查,升級才算真正完成。這些檢查應在升級前定義,讓團隊清楚“成功”意味著什麼。
驗收檢查可能包括服務啟動、登入、核心流程執行、資料讀寫、報表產生、介面呼叫、設備連接、排程任務執行、權限驗證、備份操作、監控狀態和使用者確認。具體清單取決於系統功能。
應優先測試核心功能。如果系統支援業務交易,就測試交易流程;如果支援通訊,就測試呼叫路徑或訊息流;如果支援監控,就測試警報接收和儀表板更新;如果提供資料庫服務,就測試應用存取和查詢行為。在關鍵服務未驗證前,不應把早期驗證時間花在次要功能上。
驗收還應包括日誌審查。錯誤日誌、警報資訊、失敗任務、認證錯誤、資料庫遷移資訊和整合失敗,可能在使用者發現之前暴露問題。介面看起來正常,並不總是意味著升級完全乾淨。

發佈後持續監控系統
升級後的最初數小時和數天非常關鍵。有些問題只有在真實流量、排程任務、尖峰使用或特定使用者行為下才會出現。對於關鍵系統,升級後的監控應比日常運行更主動。
監控內容應根據系統類型覆蓋 CPU、記憶體、磁碟、資料庫效能、網路流量、服務狀態、錯誤日誌、使用者工作階段、交易成功率、API 回應、佇列長度和儲存成長。團隊還應關注使用者回饋管道,因為某些問題會先被使用者感知到。
效能基準線很有價值。如果團隊知道升級前的正常回應時間、資源占用和錯誤率,就能更客觀地比較新版本表現。沒有基準線時,團隊很難判斷效能下降是新問題還是歷史問題。
升級後監控應有明確持續時間。小型系統可能監控數小時即可,關鍵系統可能需要持續數天或覆蓋一個完整業務週期。系統在正常運行條件下證明穩定前,升級不應結束。
記錄所有變更內容
文件是升級的一部分,不是可有可無的行政工作。團隊應記錄安裝了什麼版本、哪些設定發生變化、做了哪些備份、出現了哪些問題、如何解決、由誰核準,以及是否還有後續工作。
版本記錄尤其重要。未來故障排除需要知道當前運行的系統版本、資料庫版本、韌體版本、驅動版本或修補層級。如果沒有文件,後續團隊可能要重新摸清環境。
已知問題也應寫入記錄。如果某個功能需要後續調整,某個整合需要廠商確認,或某個使用者群需要再次訓練,這些事項不應只留在聊天訊息中,而應成為升級記錄的一部分。
良好的文件還能改進下一次升級。團隊可以複盤哪些步驟順利、哪些環節耗時超出預期、哪些風險被遺漏,以及哪些流程需要最佳化。每次升級都應讓組織為下一次變更準備得更充分。
總結
系統升級最重要的規則是可控變更。成功的升級應保護資料、驗證相容性、限制停機、準備回退、與使用者溝通,並在發佈後確認服務行為。升級套件本身只是整個流程的一部分。
對於業務關鍵環境,最安全的做法是把升級當作完整的維運流程:評估影響、真實測試、謹慎排程、明確責任、驗證結果並在發佈後持續監控。當這些規則得到遵循時,升級就會成為改進系統的方法,而不是可避免中斷的來源。
FAQ
是否每個系統都應在新版本發佈後立即升級?
不需要。緊急安全修復可能要求快速行動,但功能升級或大版本變更應先評估。部署前應審查相容性、業務影響、測試準備情況和回退選項。
升級前最重要的準備是什麼?
最重要的準備是確認可恢復性,包括經過驗證的備份、設定記錄、回退流程和清晰的決策規則。沒有恢復信心,即使簡單升級也可能變得高風險。
為什麼測試後升級仍然會失敗?
測試可能遺漏真實生產條件,例如高流量、特殊資料、舊用戶端、第三方整合、排程任務、權限差異或網路限制。測試環境應反映最重要的生產依賴。
升級後監控應持續多久?
這取決於系統重要性和使用週期。小型內部工具可能只需要短時間監控,而關鍵服務可能需要覆蓋高峰時段、排程任務和一個完整業務週期。
升級記錄應包含哪些內容?
記錄應包括舊版本和新版本、升級時間、負責人、備份詳細資料、變更設定、測試結果、發現的問題、回退狀態、使用者通知以及需要跟進的事項。